![]()
Introduction to sktime#
Vision statement#
an easy-to-use, easy-to-extend, comprehensive python framework for ML and AI with time series
open source, permissive license, free to use
openly and transparently governed
friendly, responsive, kind and inclusive community, with an active commitment to ensure fairness and equal opportunity
an academically and commercially neutral space, with an ecosystem integration ambition and neutral point of view
an educational platform, providing mentoring and upskilling opportunities for all career stages, especially early career
sktime is a vibrant, welcoming community with mentoring opportunities!
We love new contributors. Even if you are new to open source software development!
Check out the
sktimenew contributors guidejoin our discord and/or one of our regular meetups!
follow us on LinkedIn!
Further reading:
sktimenotebook tutorials on binderrecorded video tutorials
find a bug or type? tutorial feedback thread
Contents#
sktime provides a unified, scikit-learn-like toolbox interface to multiple time series learning tasks.
Section 1 explains what a scikit-learn-like toolbox is, using the example of scikit-learn.
Section 2 gives an overview of learning with time series and challenges in the space.
Section 3 gives a high-level engineering overview of sktime.
1. sklearn unified interface - the strategy pattern#
sktime follows the sklearn / skbase interface:
unified interface for objects/estimators
modular design, strategy patterns
composable, composites are interface homogeneous
simple specification language and parameter interface
visually informative pretty printing
sklearn provides a unified interface to multiple learning tasks including classification, regression.
any (supervised) estimator has the following interface points
Instantiate your model of choice, with parameter settings
Fit the instance of your model
Use that fitted instance to predict new data!

the above in code:
[1]:
import warnings
warnings.filterwarnings("ignore")
[2]:
# get data to use the model on
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
X, y = load_iris(return_X_y=True, as_frame=True)
random_seed = 60
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=random_seed)
[3]:
X_train.head()
[3]:
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 59 | 5.2 | 2.7 | 3.9 | 1.4 |
| 52 | 6.9 | 3.1 | 4.9 | 1.5 |
| 108 | 6.7 | 2.5 | 5.8 | 1.8 |
| 36 | 5.5 | 3.5 | 1.3 | 0.2 |
| 134 | 6.1 | 2.6 | 5.6 | 1.4 |
[4]:
y_train.head()
[4]:
59 1
52 1
108 2
36 0
134 2
Name: target, dtype: int64
[5]:
X_test.head()
[5]:
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 69 | 5.6 | 2.5 | 3.9 | 1.1 |
| 71 | 6.1 | 2.8 | 4.0 | 1.3 |
| 97 | 6.2 | 2.9 | 4.3 | 1.3 |
| 42 | 4.4 | 3.2 | 1.3 | 0.2 |
| 73 | 6.1 | 2.8 | 4.7 | 1.2 |
[6]:
from sklearn.svm import SVC
# 1. Instantiate SVC with parameters gamma, C
clf = SVC(gamma=0.001, C=100.0)
# 2. Fit clf to training data
clf.fit(X_train, y_train)
# 3. Predict labels on test data
y_test_pred = clf.predict(X_test)
y_test_pred
[6]:
array([1, 1, 1, 0, 1, 0, 1, 0, 0, 1, 0, 0, 2, 1, 2, 1, 2, 1, 0, 2, 2, 0,
1, 0, 0, 0, 0, 1, 2, 0, 2, 1, 2, 0, 0, 0, 1, 0])
IMPORTANT: to use another classifier, only the specification line, part 1 changes!
SVC could have been RandomForest, steps 2 and 3 remain the same - unified interface:
[7]:
from sklearn.ensemble import RandomForestClassifier
# 1. Instantiate SVC with parameters gamma, C
clf = RandomForestClassifier(n_estimators=100)
# 2. Fit clf to training data
clf.fit(X_train, y_train)
# 3. Predict labels on test data
y_test_pred = clf.predict(X_test)
y_test_pred
[7]:
array([1, 1, 1, 0, 1, 0, 1, 0, 0, 1, 0, 0, 2, 1, 2, 1, 2, 1, 0, 2, 2, 0,
1, 0, 0, 0, 0, 1, 2, 0, 2, 1, 2, 0, 0, 0, 1, 0])
In object oriented design terminology, this is called “strategy pattern”
= different estimators can be switched out without change to the interface
= like a power plug adapter, it’s plug&play if it conforms with the interface
Pictorial summary:

parameters can be accessed and set via get_params, set_params:
[8]:
clf.get_params()
[8]:
{'bootstrap': True,
'ccp_alpha': 0.0,
'class_weight': None,
'criterion': 'gini',
'max_depth': None,
'max_features': 'sqrt',
'max_leaf_nodes': None,
'max_samples': None,
'min_impurity_decrease': 0.0,
'min_samples_leaf': 1,
'min_samples_split': 2,
'min_weight_fraction_leaf': 0.0,
'monotonic_cst': None,
'n_estimators': 100,
'n_jobs': None,
'oob_score': False,
'random_state': None,
'verbose': 0,
'warm_start': False}
2. sktime is devoted to time-series data analysis#
Richer space of time series tasks, compared to “tabular”:
Forecasting - predict energy consumption tomorrow, based on past weeks
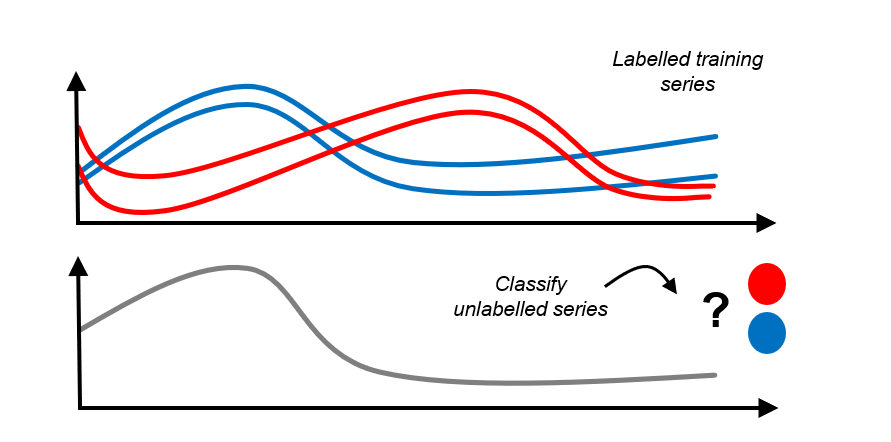
Classification - classify electrocardiograms to healthy/sick, based on prior examples
Regression - predict compound purity in bioreactor based on temperature/pressure profile
Clustering - sort outlines of tree leaves into a small number of similar classes
Annotation - identify jumps, anomalies, events in a data stream
sktime aims to provide sklearn-like, modular, composable, interfaces for these!
Task |
Status |
Links |
|---|---|---|
Forecasting |
stable |
|
Time Series Classification |
stable |
|
Time Series Regression |
stable |
|
Transformations |
stable |
|
Performance metrics for forecasts |
stable |
|
Time series splitting/resampling |
stable |
|
Parameter fitting |
maturing |
|
Time Series Alignment |
maturing |
|
Time Series Clustering |
maturing |
|
Time Series Distances/Kernels |
maturing |
|
Anomalies, changepoints |
experimental |
In the skpro companion package:
Module |
Status |
Links |
|---|---|---|
Probabilistic tabular regression |
maturing |
|
Time-to-event (survival) prediction |
maturing |
|
Performance metrics for proba predictions |
maturing |
|
Probability distributions |
maturing |
Example - forecasting#
[ ]:
# get the data
from sktime.datasets import load_airline
y = load_airline()
[9]:
import numpy as np
from sktime.forecasting.naive import NaiveForecaster
# step 1: specify the forecasting algorithm
forecaster = NaiveForecaster(strategy="last", sp=12)
# step 2: specify forecasting horizon
fh = np.arange(1, 37) # we want to predict the next 36 months
# step 3: fit the forecaster
forecaster.fit(y, fh=fh)
# step 4: make the forecast
y_pred = forecaster.predict()
[10]:
from sktime.utils.plotting import plot_series
fig, ax = plot_series(y, y_pred, labels=["train", "forecast"])

Example - time series classification#
[ ]:
# get the data
from sktime.datasets import load_osuleaf
# for training
X_train, y_train = load_osuleaf(split="train", return_type="numpy3D")
# for prediction
X_new, _ = load_osuleaf(split="test", return_type="numpy3D")
X_new = X_new[:2]
[11]:
from sktime.classification.distance_based import KNeighborsTimeSeriesClassifier
from sktime.dists_kernels import ScipyDist
from sktime.dists_kernels.compose_tab_to_panel import AggrDist
# step 1 - specify the classifier
mean_eucl_dist = AggrDist(ScipyDist())
clf = KNeighborsTimeSeriesClassifier(n_neighbors=3, distance=mean_eucl_dist)
# step 2 - fit the classifier
clf.fit(X_train, y_train)
# step 3 - predict labels on new data
y_pred = clf.predict(X_new)
[12]:
X_train.shape
[12]:
(200, 1, 427)
[13]:
y_train.shape
[13]:
(200,)
[14]:
X_new.shape
[14]:
(2, 1, 427)
[15]:
y_pred.shape
[15]:
(2,)
3. sktime integrates the time series modelling ecosystem!#
the package space for time series is highly fragmented:
lots of great implementations and methods out there!
but many different interfaces, not composable like
sklearn

sktime integrates the ecosystem - in friendly collaboration with all the packages out there!


easy search for plug&play components across the ecosystem!
Try the `sktime estimator search <https://www.sktime.net/en/latest/estimator_overview.html>`__

4. Summary#
sklearninterface: unified interface (strategy pattern), modular, composition stable, easy specification languagesktimeevolves the interface for time series learning taskssktimeintegrates a fragmented ecosytem with interface, composability, dependency management
Credits: notebook 0 - sktime and sklearn intro#
notebook creation: fkiraly, marrov
some vignettes based on existing sktime tutorials, credit: fkiraly, miraep8
slides (png/jpg):
from fkiraly’s postgraduate course at UCL, Principles and Patterns in Data Scientific Software Engineering
ecosystem slide: fkiraly, mloning
learning tasks: fkiraly, mloning
Citations & credits in academic research papers:
sktime toolbox: sktime: A unified interface for machine learning with time series
sktime design principles: Designing machine learning toolboxes: Concepts, principles and patterns
Generated using nbsphinx. The Jupyter notebook can be found here.